问题
https://www.kaggle.com/wendykan/lending-club-loan-data
数据集包含2007-2015年间的借贷数据,包含当前借贷状态(Current, Late, Fully Paid,等)以及最新的付账信息。
额外的信息包括:信用评分、金融咨询次数、住址邮政编码、所在州等。
该数据集包括约890,000条记录,75列数据。
- 查看不同借贷状态的数据量
- 按月份统计借贷金额总量
- 按地区(州)统计借贷金额总量
- 借贷评级、期限和利率(默认实际利率)的关系分析
过程
首先导入模块
1 | import pandas as pd |
使用pandas的read_csv读取csv文件
1 | df = pd.read_csv('loan.csv', low_memory = False) |
查看不同借贷状态的数据量
pandas 的value_counts()函数可以对Series里面的每个值进行计数并且排序。返回series。
1 | def get_loan_status(df): |
按月份统计贷款总量
首先把日期列中的月份提取,再按月份对贷款量分组,最后求和,返回series。
to_datetime用于获取指定的日期时间
1 | def get_total_loan_by_month(df): |
按地区(州)统计借贷金额总量
把数据按地区对贷款量分组,再求和,返回series。
groupby是非常高效的分组h函数。
1 | def get_total_loan_by_state(df): |
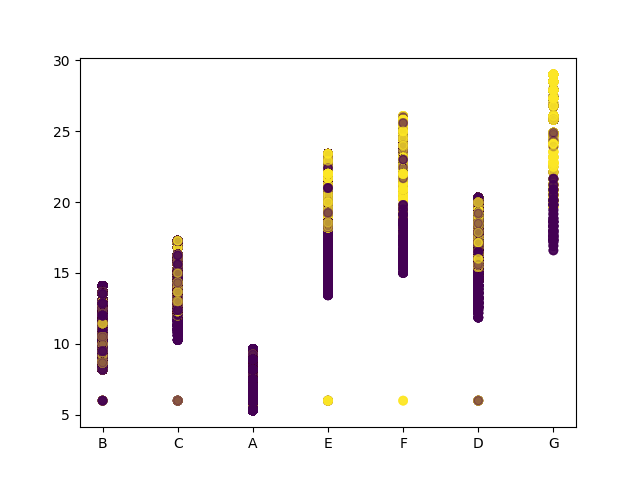
借贷评级、期限和利率(默认实际利率)的关系分析
评级为x轴,利率为y轴,绘制散点图,期限为点的颜色。
1 | def analysis(df): |
绘制散点图效果如下: